MACHINES AND HUMANS AS ALLIES IN DISASTER RESPONSE
Enhancing Disaster Response by the interplay Machine and Human Intelligence
Disaster response presents the current situation, creates a summary of known information on the disaster, and sets the path for recovery and reconstruction. During the last ten years, various disciplines have investigated disaster response in a two-fold manner. First, researchers published several studies using state-of-the-art technologies for disaster response. Second, humanitarian organizations produced numerous protocols on how to respond to natural disasters. The former suggests questioning: If we have developed a considerable amount of studies to respond to a natural disaster, how to cross-validate its results with NGOs’ protocols to enhance the involvement of specific disciplines in disaster response?
To address the above question, the research proposes an experiment that considers both: knowledge produced in the form of 8364 abstracts of academic writing on the field of Disaster Response and 1930 humanitarian organizations’ mission statements indexed online. The experiment uses Artificial Intelligence in the form of Neural Network to perform the task of word embedding –Word2Vec– and an unsupervised machine learning algorithm for clustering –Self Organizing Maps. Finally, it employs Human Intelligence for the selection of information and decision making. The result is a mockup that will suggest actions and tools that are relevant to a specific scenario forecasting the involvement of architects in Disaster Response.
The majority of scientific knowledge and humanitarian organization mission statements are published as text, which is challenging to analyze by either traditional statistical analysis or modern machine learning methods. Therefore, novel studies strengthen their efforts to create or improve methods to analyze this type of data.
This research proposes a method to analyze written knowledge from two narratives concerning disaster response; to subsequently cluster, filter, and prioritize its information regarding a specific interest. The outcome is a selection of specific literature in academic writing and humanitarian organizations that have similar approaches to the specific interest (a description of a natural disaster by the news).
The project pipeline starts by collecting data (Web scraping and APIs) — then process its modality by encoding its representation to numerical vectors (Word2Vec). The pipeline continues with an algorithm to cluster (Self Organizing Maps SOM) the texts based on their similar pattern in their numerical vectors.Ending, when a numerical vector encapsulating a specific interest (encoded query) finds its similar information from the already clustered literature.This research integrates AI with the abilities of architects, as data collectors and decision-makers to improve the quality of disaster response as it allows significantly to facilitate a) information accessibility, b) fast and direct assessment, and c) logistics decisions.

Humanitarian Organization Deployment

Academic Writing in Disaster Response
9000 abstracts from the field of disaster response were collected, using Elsevier's Scopus and Science Direct application programming interfaces (APIs) (https://dev.elsevier.com/) with the following combination of keywords: Building Safety Assessments, Housing and Disaster Response and Policy Recommendations and Disaster Response.
To pre-process the text-data, three operations were implemented: first, selection of lower-casing and de-accenting; second, removing stop words; and third, selection of words that are part of a speech (nouns, pronouns, adjectives, verbs, adverbs, prepositions, conjunctions, and interjections). To encode the text-data to numerical vectors the research uses algorithms for word embedding (a Natural Language Processing) a technique that assigns high-dimensional vectors (embeddings) to words in a text corpus, preserving their syntactic and semantic.

The algorithm used to transform the text into word embeddings is a Neural Network call Word2Vec with the method of continuous-bag-of-words (CBOW). The former learns the embedding through maximizing the ability of each word to be predicted from its set of context words using vector similarity. The output of Word2Vec is a 50-dimensional numerical vector for each word from the text corpus. To continue with the experiment, the preprocessed text (both academic writing and humanitarian organizations) was fed as training data to a Word2Vec algorithm in order to use the knowledge acquired from the previous training to create a domain-specific model Word2VecDR (this is call transfer learning). After the Word2VecDR was trained, it was able to encode all texts from the dataset into a numerical representation -every word of the text was assigned 50 numerical vectors.
Furthermore, researchers have also applied statistical operations such as mean or average value on a list of word embeddings, having successful results capturing the content of the text; examples of the former can be found in (Li et al., 2017 & Socher et al., 2014). However, when calculating the mean value or adding each word vector, the resulting vector will be an abstraction (reduced) of its content, hence, losing information. To encapsulate as much information as possible from the list of numerical vectors, the present research proposed to use Higher-Order Statics (HOS). In HOS, mean (X) and standard deviations (s) are related to the first and the second order moments –one could calculate up to n order moments. Skewness (ski) can be calculated from the third-order moments of the data distribution, which measures the direction of the tail in comparison to the normal distribution, where Y is the Median.

Clustering and representation technics assist to adequately explore the collection of data and identify clusters of similar information that share similar properties. SOM is a generic algorithm that can be used for different purposes, having an excellent (85%) performance if it is compared with algorithms that are specific for that purpose.
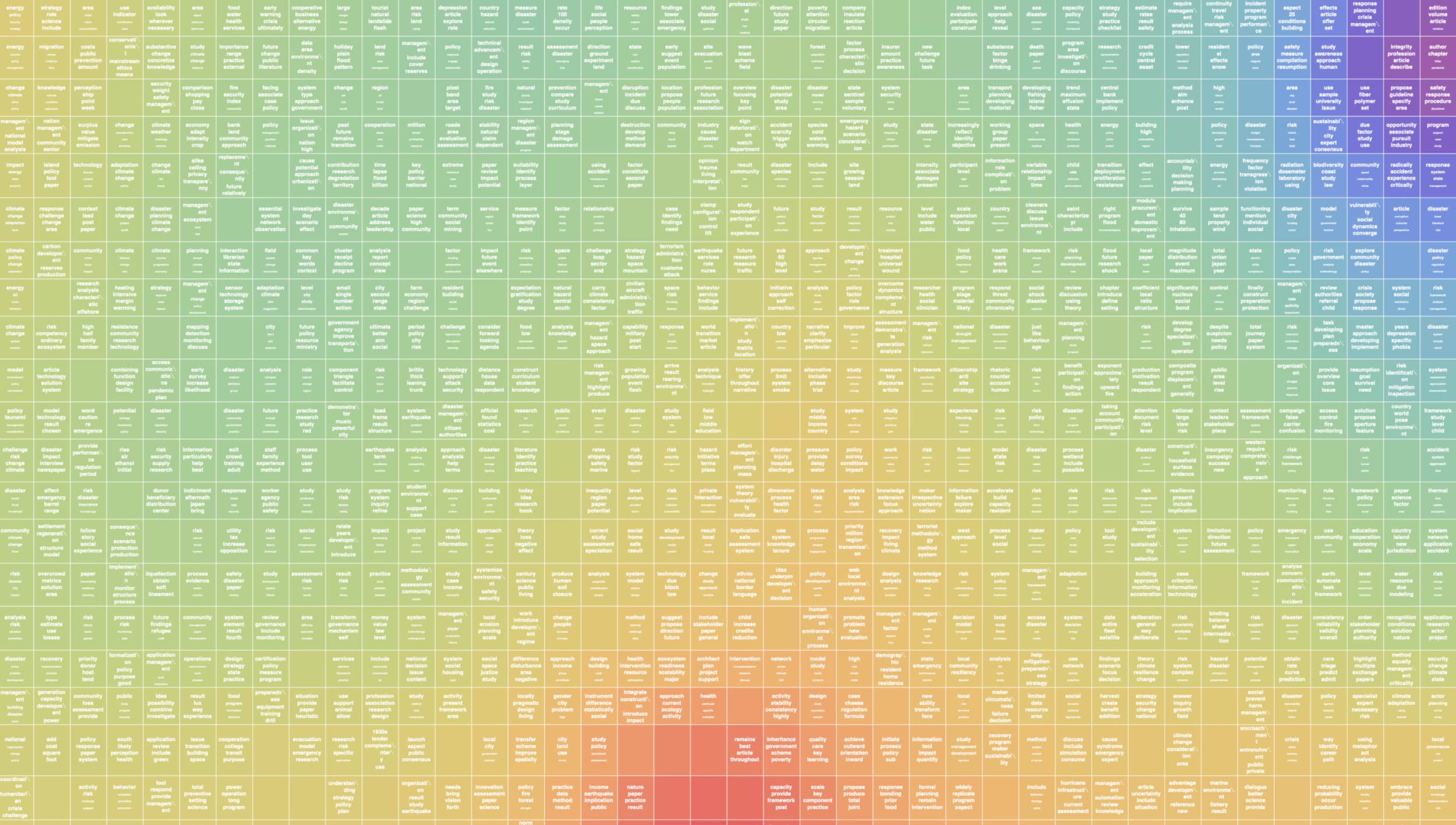
The numerical vectors representing the text from humanitarian organizations were fed as inputs into a SOM grid of 20x20. The algorithm started with an initial distribution of random weights, and over one million epochs eventually settled into a map of stable zones or clusters. The output layer of the SOM can be visualized as a smooth changing spectrum where each SOM-node has its coordinates and an associated n-dimensional vector or Best Matching Unit (BMU).
For visualization purposes, a color assigned to the weight value (n-dimensional vector) of each BMU and a list of keywords are displayed together. The keywords are the most common terms used in the texts that are clustered in each SOM-node. The size of the word represents the number of occasions the word appeared in the group of text.

SOM10X10 of Academic Writing

SOM 10X10 of Humanitarian Organizations
An additional step in the pipeline is proposed to filter the number of humanitarian organizations, based on similar interests shared with academic writing. When a new dataset is fed as input to a trained SOM, each data point measures its Euclidean distance to each BMU, thecloses the distance, the better the data point fits that node.

Selection of cells based on common terms with Academic Writing

Selection of cells based on selected Academic Writing with Architectonic focus
The filtered dataset of humanitarian organizations (1082) was joined with the dataset of Academic writing (8364), creating a new dataset of 9446 texts. The aforementioned texts were fed as input in a SOM grid of 10x10 that after a million iterations, settled into a map of clustered texts. As described in the contribution, the paper addressed the intention of joining two discourses regarding disaster response. The trained SOM grid of 10x10 (Fig. 6) achieves the objectives as it encapsulates both discourses in an organized manner thatserves as a ground for prioritization and selection of information depending on a specific interest.

SOM of 10X10 trained with joined data form Filtered Humanitarian Organizations (1082) and Academic Writing from the field of Disaster Response (8364)
As explained in the introduction, this research has a specific focus on post-disaster assessments, especially in disaster response, where information should be concise and arrive on time for decision making. The case study selected from 2016 is one of the different scenarios investigated in the research. The images below depict four organizations and four studies were selected from the cluster of texts belonging to the BMU assigned to the query.


Gallery